Dreaming — the loop pointed inward.
Every autonomous loop in this book points outward. The swarm reads the codebase. Cron reads the calendar. Run-until-done reads the task. Dreaming is the first one pointed at the agent's own memory — the one index a wrong write quietly poisons. So it gets less rope, not more.
Anthropic shipped Dreaming in Managed Agents as a thing that can auto-write memory. I built the local Claude Code twin deliberately weaker — propose-only — because the one record I can't afford to corrupt is the one I curate by hand. This page is the operator's runbook: the pipeline, the refusals, the receipts, and when not to. The story lives in Chapter 44.
Jump to section tap to open
The loop pointed inward
The book has spent forty-three chapters handing agents more rope. The swarm fans out across a codebase. Cron runs while you sleep. Run-until-done loops until an evaluator says stop. Chapter 43 let a second model delete ninety thousand lines unsupervised. Every one of those points at something external — code, a schedule, a task — where a mistake is visible and reversible.
Dreaming points at your memory. The curated index every future session reboots into. A wrong write there isn't a bad diff you revert; it's a confident lie your agent reads back to you for weeks. So this is the loop I gave the least rope, on purpose. It reads everything and writes nothing.
The pipeline — five stages, one model
Digest, extract, verify, review. The model runs in exactly one of those stages. Everything else is plain deterministic code — which is the only reason a week of 5-megabyte transcripts is even tractable.
Pick recent sessions deterministically: skip the live, still-being-written session and any already-dreamed (a ledger keyed on file mtime + bytes). Window and cap — default five sessions, seven days. Never "all." 483 transcripts in a week is a token bomb for near-zero yield on a stale corpus; defer the rest loudly.
A plain Python pass turns a 5.8 MB session transcript into ~24,000 characters by keeping the human prompts and the assistant's prose and dropping the tool plumbing. This happens outside the agents, because a 5 MB transcript cannot enter one — that's Rule 5: code does the heavy deterministic work, the model only judges what code hands it.
Read-only Explore agents fan out, one per session — OpenClaw logic, the read-broadly-summarize-cite shape from Rick. Each candidate lesson must cite a verbatim quote from the digest. The agents have no write tool and structurally cannot touch memory.
Re-grep each cited quote against the raw .jsonl — not the lossy digest the agent read — decode-aware, because the transcript stores text JSON-escaped. "Grounded in the digest" is not "grounded in what happened." Real quotes survive; invented ones drop.
Write a dated review-<date>.md — each candidate as Claim / Why / How-to-apply / the verified quote + source session, grouped NEW vs ⚠DUP — and update the ledger. It never writes to memory/. The human, plus the existing /learn skill, stays the writer.


The five refusals — the safety architecture
These aren't guardrails bolted onto a writer. They're the architecture. The single most destructive thing the whole pipeline can do is write one markdown file — and that's by design, not by limitation.
- 1 — Never auto-write, delete, overwrite, or consolidate a memory. Propose-only is both the default and the ceiling; the most it can do is surface a review file.
- 2 — Never schedule it via cloud cron. Cloud schedulers run in a remote sandbox with no access to local
~/.claude/— a scheduled dream wakes to an empty disk and mis-reports. Locallaunchdonly, still propose-only. - 3 — Never process "all" sessions. Window, cap, and defer loudly. No silent truncation.
- 4 — Never trust an agent's self-report. Agents have no write tool; only the main loop writes, and it ground-truths by re-statting the file it wrote.
- 5 — A candidate with no raw-transcript quote match is dropped. No exceptions.

The receipts — two runs, stated honestly
Two real runs the day it was finished. Read the numbers in their honest form: fifteen candidates surfaced, fifteen quote-verified, zero dropped, fourteen net-new, and one the tool itself flagged as a duplicate. Zero dropped means nothing on these runs was fabricated — not that the verifier caught a hallucination. Its anti-hallucination power (fabricated quotes drop, real ones survive the raw re-check) I proved in a separate adversarial test, not here.
| Run | Sessions | Candidates | Verified | Net-new | Flagged dup | Missed dup |
|---|---|---|---|---|---|---|
| Single-project | 3 | 3 | 3 | 3 | 0 | 0 |
| Cross-project | 6 | 15 | 15 | 14 | 1 | 2 |
Digest economics: largest single transcript 5.8 MB → ~24,000-char digest (~240×). Roughly 16% of conversational mass was signal in the one session measured; toolUseResult alone was 732 KB. The MEMORY.md index it protects sits at 170/200 lines.

The run where it told me the truth about its own blind spot
On the cross-project run it flagged one duplicate — a workflow rate-limit lesson — against the home index, and missed two: two HubSpot credential-rotation lessons came back as clean net-new, even though I'd saved both by hand days earlier. That looks like a failure. It's the opposite. The tool dedup-checks against the portfolio index, which holds one-line pointers, not detail; the two lessons lived one level down inside a project's own memory, a place that index points at but never reads. It didn't miss a duplicate it could see — it correctly returned "new" for two candidates it had no structural way to know were already filed. And the cost asymmetry is the whole case for propose-only: the worst that miss did was put two suggestions in a file I delete in three seconds. The auto-writing version, with the identical blind spot, writes a confident duplicate into an index I don't find corrupted for three weeks.
The method, shown
This page and Chapter 44 were themselves planned by a swarm: five perspective agents in parallel, then a reconciler, then a red team whose job was to attack the result. The red team caught me overstating one of the receipts above and made me verify it against disk — the exact discipline this page preaches, applied to itself. The fan-out below is the method, not just the subject.

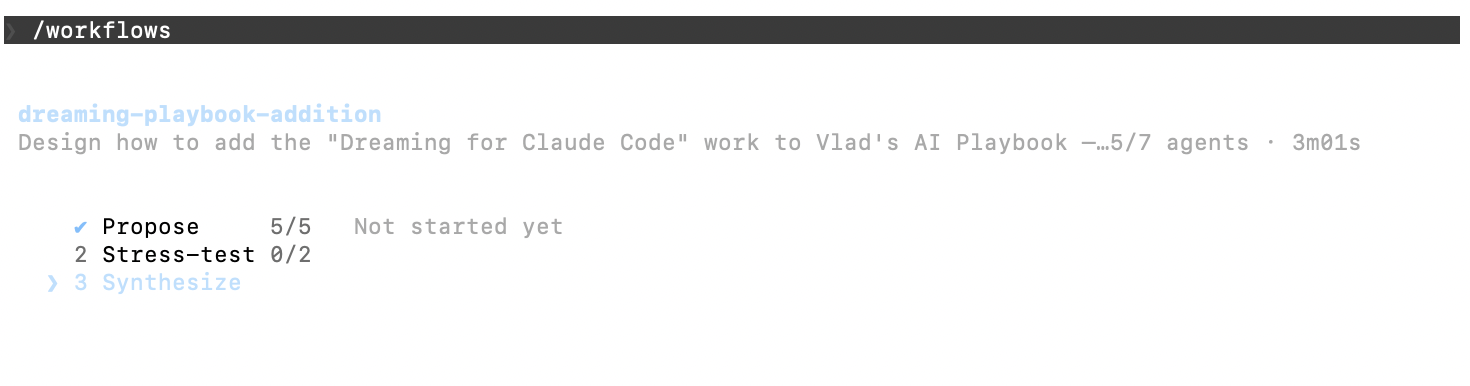
The exception to Chapter 7
Chapter 7 tells you to make AI work while you sleep — put it on a cron. Dreaming is the obvious nightly cron, and refusal number two forbids exactly that. The two aren't in conflict; they're resolved by a rule the cron chapter doesn't have to state because most tasks read cloud data: schedule a task where its data lives, or don't schedule it.
Two-way link: Ch 7 — Scheduled Tasks · Ch 44 — Dreaming.
When not to run it
Don't dream a fresh or empty corpus — there's nothing to surface. Don't dream the live session; it's still being written. Don't dream "everything" after a long gap — window it, or you pay for a swarm to convene on a stale pile for near-zero yield. And don't promote it to auto-write before you've earned it.
The failure mode that actually kills a tool like this isn't a crash — it's quiet abandonment. It surfaces nothing useful for a few weeks and you drift away from running it. So it ships a yield-floor tripwire: three runs in a row that surface zero new candidates and it prints "DREAM IS PROPOSING NOTHING — extractor may be mis-tuned or the corpus is saturated." Now abandonment is a decision, not a drift.
Do this Monday
Don't build the pipeline yet. Steal the principle. At the end of your next heavy session, tell the agent: re-read this whole transcript and propose, in writing, what's worth remembering — and make it quote the exact line for each one. Then you read the list, throw out the noise, and save the keepers yourself. That's dreaming, by hand, before you ever automate it — and it's the version that teaches you whether the automated one is worth building for how you actually work.
Related: Ch 44 — Dreaming (the narrative) · Ch 37 — the memory layers it curates · Ch 3 — why it forgets you · Ch 32 — Rick & OpenClaw · The Swarm — the fan-out it runs on · Ch 7 — and why not to cloud-cron this one