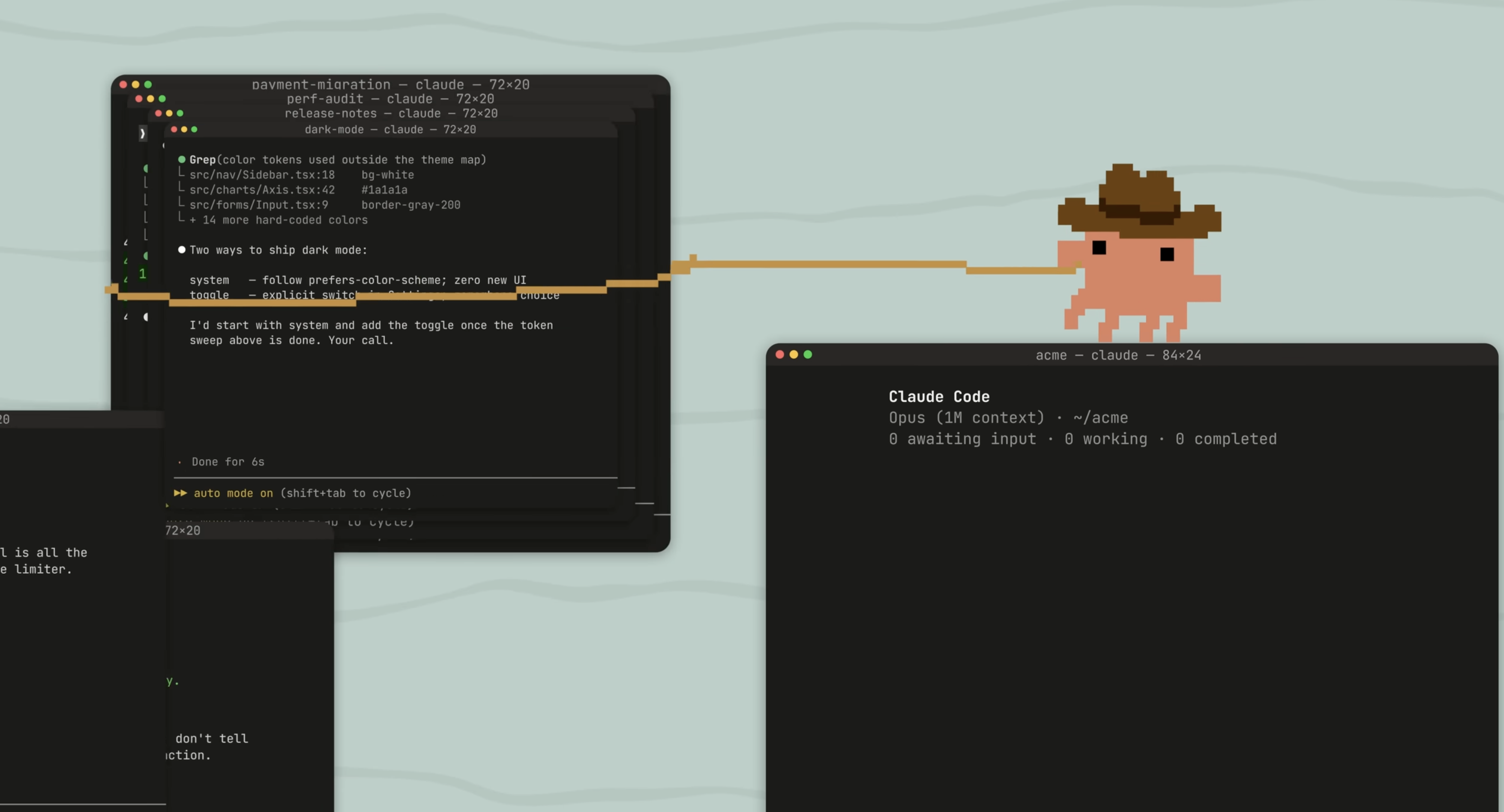
One agent is a chat. Twenty agents is a portfolio.
The deep version of Chapter 6 — the architecture diagrams, the ten swarm skills I've shipped, the seven patterns I actually use, the orchestration prompts I'd hand to a friend, and the three things that quietly break a swarm. This page is what Ch 40 kept gesturing at — the next step up from a clever single-instance prompt.
Interactive visualizer below. Patterns you can run on Monday. The skills you can install before lunch.
Jump to section tap to open
Why swarms exist
The cleverest single-instance prompt you'll ever write tops out at a ceiling the model imposes — one context window, one chain of reasoning, one shot. A swarm lifts the ceiling by changing what you're running. Not one bigger model. Many same-sized models, each in a clean context, each pointed at one slice of the problem, returning to a conductor who never had to hold the whole symphony in its head.
The shift is structural, not stylistic. A single instance has to balance four perspectives in one answer; four instances each get to be one perspective. A single instance loses the thread on a long task; four instances each finish before their threads go anywhere. A single instance running for fifteen minutes consumes fifteen minutes; four instances running in parallel consume four wall-clock minutes of yours. The model didn't get smarter — the architecture got smarter.
I wrote this Playbook with a 15-agent swarm in roughly six minutes of wall-clock time (the story is in Chapter 6). I run a 20-agent swarm whenever a portfolio company wants a complete strategic plan from scratch — the /swarm-strategic-plan skill is the productized version of that pattern. I run a 3-agent swarm every time I hit a bug I can't reason through alone (/debug-swarm). The shelf is real. The patterns are stable. The compounding is the same compounding that all leverage has — once you've used it, the sequential version of your work starts to feel like writing email by candlelight.
That distinction is the whole game. Most operators who try parallel agents and bounce off have built a group chat. You want a chain of command — one conductor, N section leads, each section lead in its own clean context window, returning only finished phrases to the conductor.
The four patterns (interactive)
Four shapes cover ~90% of operator swarm work. Pick one, hit Run, watch the topology animate. Then pick a different one and see how the dispatch order changes. This is the same widget that lives in Ch 06; embedded here so you can poke at it without context-switching.
Fan-out is the canonical swarm: one task decomposes into N independent subtasks, each subtask gets its own agent, and the orchestrator recombines. Use for: writing a multi-chapter book, drafting N landing pages, auditing N domains, exploring N variant designs. The agents never see each other's work; the orchestrator does the integration.
Pipeline is the assembly-line shape: draft → critique → revise → publish, four agents in series. Use for: editorial workflows, code-review-then-fix loops, contract drafting where each pass has a distinct role. Sequential, but each stage has a clean context — no accumulated cruft from earlier turns polluting the final pass.
Map-reduce is fan-out's cousin for data: N workers chew chunks of a large input, one reducer merges. Use for: summarizing 500 documents, extracting structured fields from a directory of PDFs, classifying a backlog. The map stage is embarrassingly parallel; the reducer is where the design lives.
Adversarial is the dialectic shape: proposer + critic + arbiter. Use for: high-stakes decisions where you want a deliberate red-team, contract negotiation simulations, "kill or ship" calls. The critic agent's job is to find what the proposer missed; the arbiter's job is to integrate.
The wave pattern — 5 × 4 = 20 agents
The pattern I use most often for big work is five waves of four agents each — twenty specialists in roughly thirty minutes of wall-clock time, controlled by one orchestrator reading one master BRIEF. The shape is in the /swarm-strategic-plan skill but the architecture generalizes: pick a project, write a one-page BRIEF that every agent must read first, then dispatch waves of three-to-four agents that don't overlap on filesystem.
Why four agents per wave, not ten. The empirical sweet spot is three to four. Five and you start to see filesystem contention (two agents writing the same file, race conditions in shared output dirs); six and the orchestrator's own context starts to thrash; seven and you've created a group chat without realizing it. Three to four is the operator's number — small enough to track, big enough to actually parallelize.
Why waves, not all-at-once. Twenty agents in one shot is a coordination nightmare — every agent re-reads the same BRIEF, the orchestrator can't tell which output came from whom, and the synthesis step has nothing to integrate against. Waves let wave N+1 read wave N's output as fresh context. That's how a "strategic plan" becomes coherent instead of twenty disconnected SaaS PRDs.
The five waves I default to (concrete from the skill, adjust per venture):
- Wave 1 — Foundation. Vision & positioning · business plan · monetization · market analysis. The "what is this even" wave.
- Wave 2 — Operations. Sourcing · product/format rules · venue/production · legal/safety. The "how do we make this real" wave.
- Wave 3 — Brand & GTM. Brand identity · marketing/hype · distribution/access · talent/atmosphere. The "how do we make people care" wave.
- Wave 4 — Revenue. Revenue model + P&L · sponsorship architecture · streaming/digital · merch/licensing. The "how do we make money" wave.
- Wave 5 — Tech & Ecosystem. Tech stack · domain personas · community platform · investor pitch outline. The "how do we scale" wave.
Total output of one run: 25 markdown files, ~62K words, ~3 hours wall-clock. That's the AFC playbook output and it's reproducible against any greenfield venture with a real thesis. The whole point of having a productized skill instead of a one-off prompt is that the architecture is now infrastructure — you don't re-design the swarm each time, you just write the BRIEF.
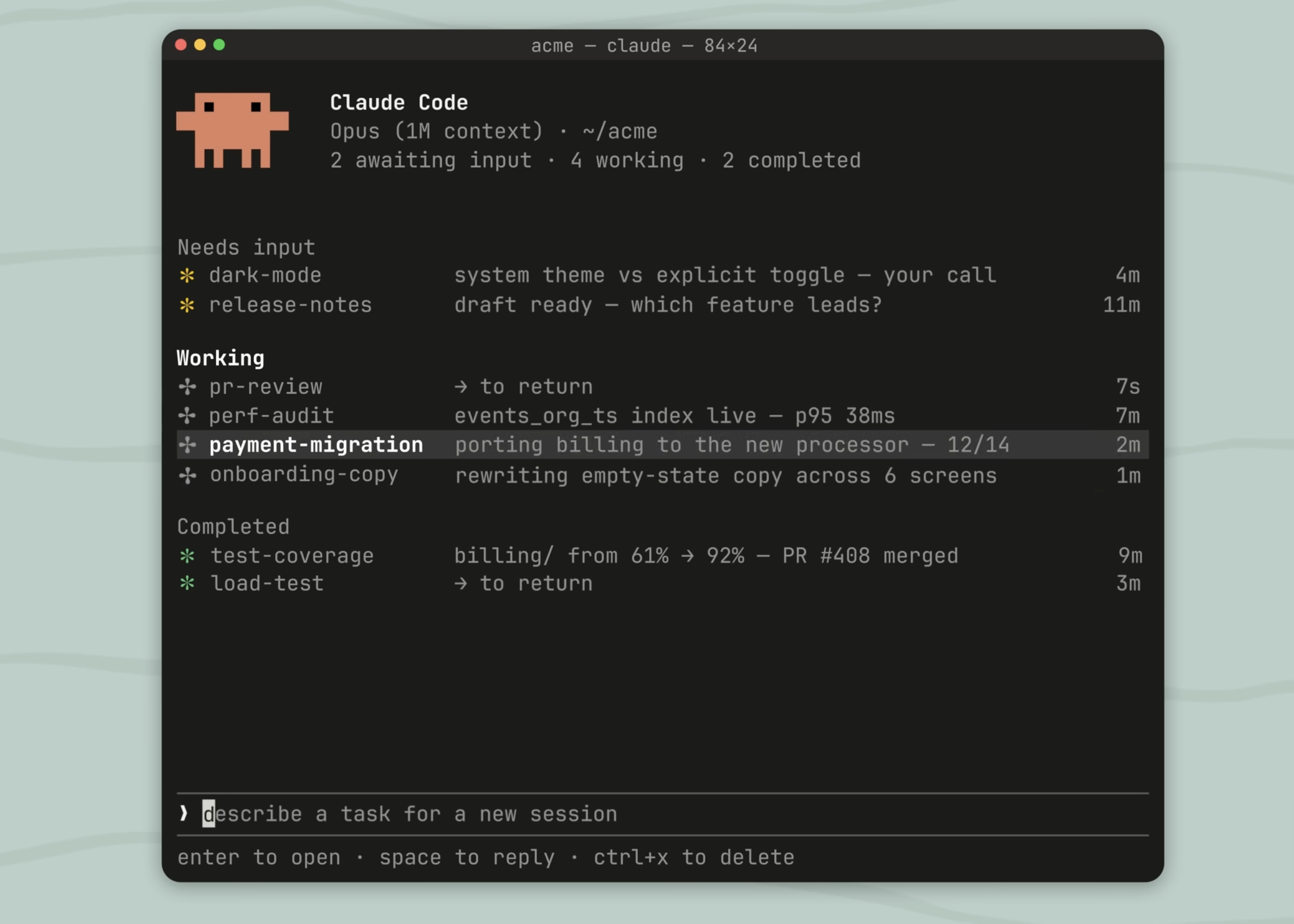
My current swarm skill shelf
Ten skills I actually use. Each one is a folder in ~/.claude/skills/ with a SKILL.md that the model loads on demand. The "shape" column tells you how many agents and what topology; the "use" column tells you when to reach for it. Install any of these by cloning the folder into your own ~/.claude/skills/ — they're MIT-spirited (read the LICENSE in each), portable across Claude Code sessions, and version-controllable in git.
Greenfield venture planning. Scaffolds 25 markdown docs covering vision/business/ops/brand/revenue/tech/investor. Each agent reads the master BRIEF first; locked constraints prevent drift.
~/.claude/skills/swarm-strategic-plan/ Hypothesis-driven debugging. One agent looks at data/state, one at code/control-flow, one at integration/IO. They don't edit — they gather evidence. Operator decides the fix.
~/.claude/skills/debug-swarm/ Codebase security + quality audit. Auth, email, payments, data layer, error-handling, secrets — each domain gets its own reviewer. Background tool calls; single-message dispatch.
~/.claude/skills/audit/ After spawning a 3-4 agent wave, verify each delivered. Catches silent failures (agent returned OK but left no commit), race conditions (two agents wrote the same file), scope drift (agent edited outside its assigned dir).
~/.claude/skills/agent-wave-verify/ External email-deliverability audit of N sending domains. Script-not-swarm collection (resumable cache), then swarm of subagents on findings, then synthesis into a client-ready interactive HTML.
~/.claude/skills/folderly-external-audit/ Audits landing-page + Day-1 fulfillment + welcome email side-by-side for tier-name / price / refund-window / cadence contradictions before money moves. Each agent owns one document; arbiter integrates.
~/.claude/skills/cross-trio-audit/ Inspects a scope (file / module / repo) with parallel agents looking for likely bugs. Returns findings with file paths, severity, and proposed fixes.
~/.claude/skills/bughunter/ Architecture, correctness, performance, security, test coverage in one orchestrated pass. The PR-or-module review that feels like having four senior engineers on the same diff.
~/.claude/skills/ultrareview/ Systematic web-app QA across critical/high/medium/cosmetic tiers. Finds bugs, then iterates fixes (commit per fix, re-verify). The "test and fix" loop, productized.
~/.claude/skills/gstack-qa/ Reviews a diff against base for SQL safety, LLM trust-boundary violations, conditional side effects, structural issues. The agent that catches the things `eslint` doesn't.
~/.claude/skills/gstack-review/ Seven swarm patterns I actually use
The four architectures above (fan-out / pipeline / map-reduce / adversarial) are the shapes. These seven are the patterns — recipes that recombine the shapes for specific kinds of work. Each one is a lesson I paid for in failed runs before it became a rule.
Wave 1 = locked CANON brief, every agent reads it first. Wave 2 = adversary that tries to break the false premises. Catches load-bearing assumptions a friendly swarm would have shared and propagated.
For 'redesign this' tasks: 3 agents × same data injected inline × different aesthetic brief. Comparison set, not single answer. Use when the right answer is in the question "which one feels right."
3 agents × different philosophies (topical / action / question) for titling, voice, copy. Produces a decision surface for the editor, not a single 'best' draft. Better outputs because the choice is visible.
Same prompt to GPT/Claude/Gemini/Kimi (OpenRouter export = N proposals). Then 4 lens-judges score all proposals. Synthesis separates 'best overall' from 'best for the stated goal.'
For audit-N-external-things tasks: don't spawn N parallel agents — write a deterministic Python collector with smoke-test + resumable cache. One canonical JSON feeds every artifact. INDETERMINATE ≠ clean. (The Folderly pipeline lives here.)
For N UI variants from one dataset: agents emit a template with a `/*__DATA__*/` token; main agent injects canonical JSON. Kills drift, dodges Edit-denial, sidesteps watchdog timeouts on long tool chains.
The 'no parallel' rule applies to scarce resources (file contention, API rate limits). It does NOT apply to demand-tests where each agent hits a different external system. Re-evaluate the rule against actual scarce resource before honoring it.
Each of these patterns earned its place by failing first. The CANON-lock pattern came after a 4-agent doc swarm propagated the same wrong premise four ways. The script-not-swarm collection came after a 90-domain audit kept losing partial results to mid-flight crashes. The data-injection-slot swarm came after Edit-tool denials silently dropped half a UI variant's content. Every rule has a receipt.
Orchestration prompts to steal
The prompts the conductor sends to the section leads. These are the parent-agent dispatch prompts I actually run. Paste them into Claude Code in your own repo, swap the bracketed slots, ship.
Prompt 1 — the universal subagent dispatch envelope
Every subagent prompt I send wraps the same shell. Three guarantees, in this order. Without them, agents return content that gets silently dropped or work that contradicts the orchestrator's plan.
READ FIRST: <PATH>/BRIEF.md and <PATH>/ROADMAP.md. Don't contradict
them. Hard constraints in BRIEF.md are non-negotiable.
YOUR TASK: <one-paragraph specific task>
OUTPUT PATH: <PATH>/<folder>/<FILE>.md
WORD COUNT: <range>
VOICE: <one-line voice cue, or "match BRIEF.md tone">
If the Write tool is denied at your permission scope, return the full
markdown content INLINE in your final message so the parent agent can
save it via Write directly. Do not lose the content.
If you cannot complete the task as specified, return a SHORT structured
failure report (200 words max) explaining what was missing — do not
hallucinate content to fill the file.The third paragraph is load-bearing. Subagents spawned at deeper permission scopes than the parent often fail the Write call silently. Frame every dispatch prompt as "return content inline as the fallback" and the orchestrator catches the work even when the filesystem layer fails.
Prompt 2 — the 6-agent code audit (verbatim from /audit)
Six specialized reviewers, single message, parallel dispatch. Each one gets a domain (auth / email / payments / data / errors / secrets) and the same codebase scope. Background tool calls so the orchestrator's context doesn't fill up with their working memory. The full skill is at ~/.claude/skills/audit/SKILL.md; the dispatch shape is:
Launch ALL 6 agents in parallel (single message, multiple tool calls).
Each uses subagent_type: "feature-dev:code-reviewer" with
run_in_background: true.
# Agent 1 — Auth & User Repository
# Agent 2 — Email & Notifications
# Agent 3 — Payments & Webhooks
# Agent 4 — Data layer & migrations
# Agent 5 — Error handling & logging
# Agent 6 — Secrets & .env hygiene
Each agent: scan the assigned domain in the codebase, return
findings as a markdown report with severity (CRITICAL/HIGH/MEDIUM/LOW),
file paths and line numbers, suggested fix.
Background mode: each agent runs to completion independently. The
orchestrator waits for all six task-notifications, then synthesizes
the unified audit report.Prompt 3 — the BRIEF.md template (every wave reads this)
This is the master document for a 20-agent run. Every agent in every wave reads it first. The HARD CONSTRAINTS section is the load-bearing one — agents honor refusals better than aspirations.
# <Venture Name> — Master BRIEF
## Vision
<one-paragraph manifesto>
## Why now
<4-6 inflection points>
## Positioning wedge
<one sentence>
## Founder context
<one paragraph: owner / advisor / portfolio>
## 5 brand pillars (LOCKED, with anti-definitions)
1. <pillar> — IS <thing>, IS NOT <thing>
2. ...
## HARD CONSTRAINTS (numbered list of things we will NOT do)
1. <refusal>
2. <refusal>
3. <refusal>
## 4 phases (with goals + tests)
...
## North Star Metric
<single number>
## Open questions for the founder
<list>The hard-constraints list is the load-bearing artifact. Spawned agents will obey numbered refusals far more reliably than positive instructions; a swarm without this section drifts across all 25 docs by wave 3. Steal the pattern from ~/Desktop/AI Products/AFC/BRIEF.md — that's the live template.
Three things that quietly break a swarm
Every one of these I learned the hard way. Watch for them on the third run, when the failure is invisible and the orchestrator says "all agents complete" with nothing useful to integrate.
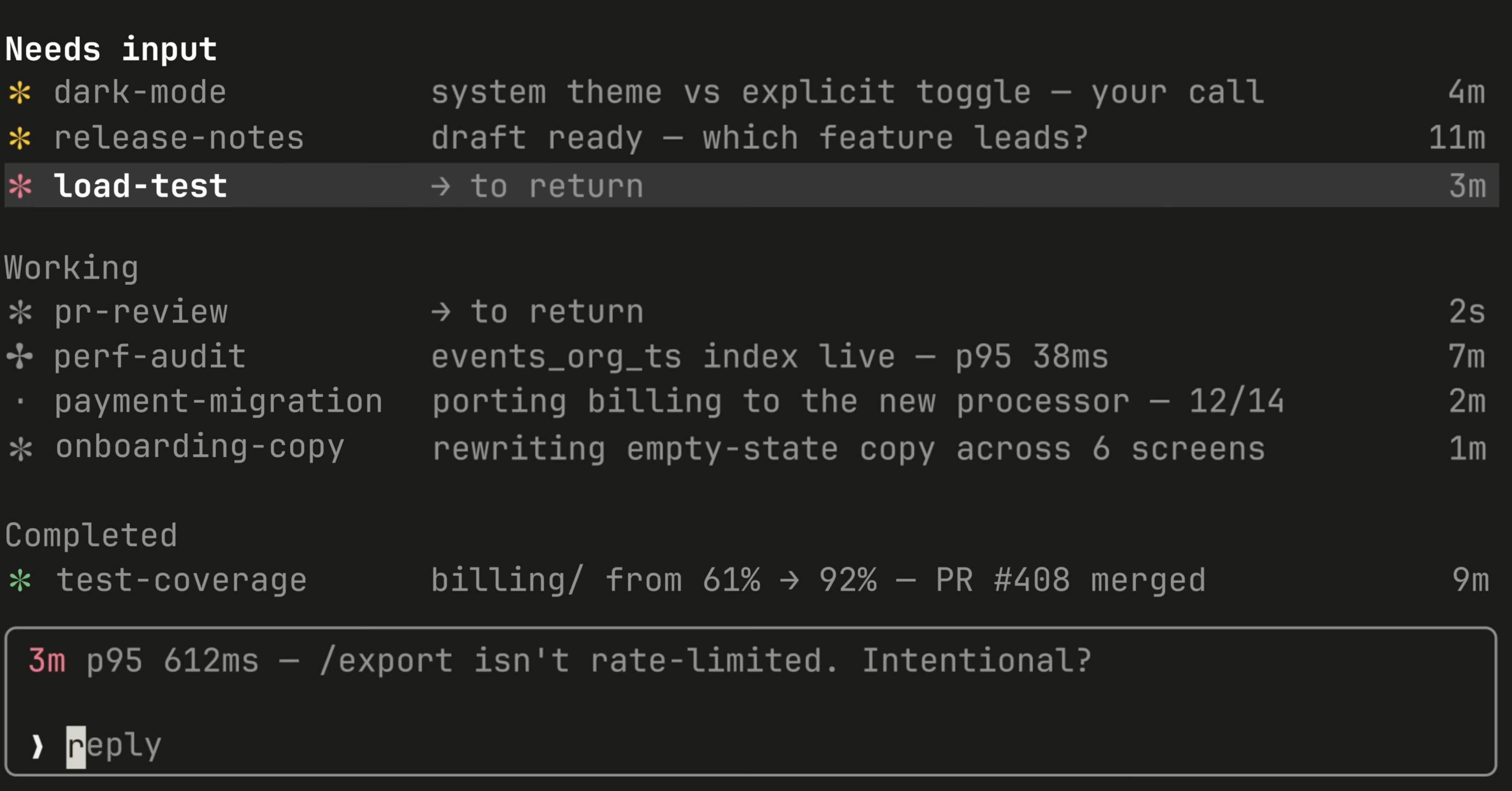
One — the 600-second watchdog stall. Long-running general-purpose agents die right before writing their deliverable. Around the eight-minute wall-clock mark you'll see the agent return "OK, completed" with zero output token usage and no file written. The fix: keep individual agent scope under eight minutes wall-clock, write the deliverable yourself in the main context if the agent stalls, use the /agent-wave-verify skill to catch the silent failure before you ship synthesis.
Two — filesystem contention with 5+ agents. Three to four agents per wave is the empirical sweet spot. Five and you start getting two agents writing the same file, race conditions in shared output dirs, or one agent reading a file while another is mid-write. The orchestrator can't see the contention — it just sees one agent's content land on disk and another agent's content vanish. The fix: cap waves at four, use distinct output paths per agent (each agent writes to <PATH>/<agent-N>/... not shared dirs), and verify between waves.
Three — load-bearing false premises in the BRIEF. If wave 1 codifies a wrong premise into the BRIEF — "the customer is X" / "the wedge is Y" — every agent in waves 2-5 inherits the error and propagates it across 20 documents. Plans built on false BRIEFs look polished and are useless. The fix: add a wave-2 adversary whose entire job is to red-team the BRIEF before further waves go out. The CANON-lock + red-team pattern is exactly this — Wave 1 locks, Wave 2 breaks, Waves 3-5 build on what survived.
The between-wave audit (don't skip it)
The single skill that's saved me the most agent-wall-clock is /agent-wave-verify. It runs between waves and checks four things: each agent's output file exists, the file has actual content (not just a stub or error message), no two agents wrote to the same path, and no agent wrote outside its assigned directory.
The dispatch is one Bash call per wave; the verification is deterministic, not LLM-judged. Either the file exists or it doesn't. Either the LOC is above a threshold or it isn't. Either the commit hash advanced or it didn't. That determinism is the point — LLM-as-judge for "did the agent succeed" is exactly the kind of vibes-judgment that lets silent failures through. Code answers.
# Between-wave verification (Bash, not LLM)
for agent in agent-A agent-B agent-C agent-D; do
output="./output/$agent/deliverable.md"
if [ ! -f "$output" ]; then echo "MISSING: $agent"; continue; fi
loc=$(wc -l < "$output")
if [ "$loc" -lt 50 ]; then echo "STUB: $agent ($loc lines)"; continue; fi
echo "OK: $agent ($loc lines)"
doneThe skill productizes this — it runs the check, surfaces the stubs and the missing files, and tells you which specific agent to respawn. The pattern transfers to any swarm: never trust "all agents completed"; verify deterministically before you synthesize.
When NOT to use a swarm
The honest counterweight. Swarms are leverage; not every task has a leverage point that a swarm fits.
Single-step tasks. "Write me one email." "Summarize this document." "Pick a name." One agent is fine. A swarm here is theatre and costs three times the tokens for no quality gain. The clue is that you can describe the deliverable in one sentence and the answer is in one place.
Tasks where the agents would need to talk to each other. If the work genuinely requires negotiation between perspectives that build on each other turn-by-turn, you don't want a swarm — you want a pipeline (sequential, each agent reads the prior agent's output) or a single instance with a structured thinking pass. Swarms thrive when subtasks are independent. The moment they need to coordinate, you've built the group chat.
Filesystem-bound tasks with one canonical output. "Update this one config file." "Apply these three migrations in order." Filesystem contention kills swarm value here; a single sequential agent finishes correctly faster than four parallel agents racing to a single file.
External-rate-limited tasks where the bottleneck is the API, not your time. If you're hitting a vendor at 60 req/min, four agents hitting it in parallel just hit the same rate-limit four times. The script-not-swarm pattern wins here — deterministic Python with proper backoff beats vibey parallel agents.
Cheap tasks where the orchestration overhead beats the savings. A swarm has fixed coordination cost: writing the BRIEF, dispatching agents, verifying between waves, synthesizing outputs. For tasks that would have taken five minutes sequentially, the swarm overhead exceeds the gain. The threshold I use: if a single agent would take more than fifteen wall-clock minutes, consider a swarm. Less than that, just run it.
Anti-patterns to red-flag in your own work: "I want to feel productive so I'll spawn four agents" (the swarm is for leverage, not for the feeling of leverage); "this prompt is hard so I'll split it" (split it after you've named the parts, not because you're stuck); "four perspectives is more thorough" (only if the four perspectives are actually different — most "four perspectives" requests are one perspective rephrased).
Do this Monday
Pick one of these three. Whichever fits your week.
Path A — debug-swarm. The next bug you can't reason through, run /debug-swarm ". Three read-only investigators (data, code, integration) return findings in parallel; you decide which fix matches the evidence. Fifteen minutes from typing to evidence in hand. If the skill isn't installed, clone ~/.claude/skills/debug-swarm/ from this Playbook's repo and drop it in your own ~/.claude/skills/.
Path B — audit. The next deploy you're nervous about, run /audit on the codebase first. Six parallel reviewers cover auth, email, payments, data layer, error handling, secrets. Findings come back with file:line and severity. The deploy goes out with fewer surprises in the post-deploy logs.
Path C — swarm-strategic-plan. The next portfolio idea you've been sitting on, run /swarm-strategic-plan. Twenty agents in five waves over ~3 hours produce a complete 25-doc strategic plan in the genre of the AFC playbook. You'll have more strategy than you can read in one sitting — most operators don't have that problem, and the ones who do can afford the cost.
Related: Ch 06 — The Swarm (the original) · Ch 40 — Prompting, the Knob · Ch 05 — Skills · Ch 16 — Hooks & Subagents · Vlad's full CC setup · Resources library (orchestration prompts)