What the labs ship, and what it changes for operators.
External papers and benchmarks that materially shift how the book's patterns hold up. Not a literature review — only the findings that change what you should do Monday morning. Each note has the receipt, the operator implications, and the chapters it informs.
- June 2026 · 3 notes
- 2026-06-10 economics
The subscription subsidy, quantified — SemiAnalysis prices a $200 plan at up to $8,000 of compute
Flat-rate plans go underwater past ~10–20% utilization. The grid explains every limit you've ever hit — and why the meter is coming.
6 receipts · 4 implications · 4 chapters · ~2 min · confidence: medium
SemiAnalysis (X thread, Tokenomics model) · third-party analyst model with stated assumptionsThe findingSemiAnalysis published the grid that turns a vibe every heavy operator has had — "this plan can't possibly be profitable on me" — into numbers. Two tables from their Tokenomics model, both reproduced below. First, the option value: a $20 claude-pro can draw roughly $400/mo of API-equivalent compute at full utilization; claude-max-20x at $200 can draw ~$8,000; chatgpt-pro-20x at the same $200 can draw ~$14,000 — 20×, 40×, 70× the sticker.
Second, margin by utilization, under one stated assumption: API list prices carry a 75% gross margin, so cost-to-serve = 25% of API-equivalent value. claude-pro and claude-max-5x break even when the average user consumes 20% of their cap; claude-max-20x at 10%; chatgpt-plus and chatgpt-pro-5x at 11.4%; chatgpt-pro-20x at just 5.7%. At full utilization the 20x tiers run −900% (Anthropic) and −1,650% (OpenAI) gross margin.
Three honest discounts before you quote this anywhere: it's an analyst model, not provider financials — the 75% assumption does the heavy lifting; "max possible spend" is a ceiling, not a typical user; and the margin column is about the AVERAGE user — providers price on the pool, which is exactly why an individual heavy operator gets cross-subsidized by the light ones.
The operator read cuts two ways. Today: if your utilization sits above the break-even row — and anyone running overnight loops or swarms does — your plan is the cheapest frontier compute on sale, full stop. Tomorrow: this is now a thrice-confirmed pattern, not a hot take. Altman said it in plain text in January 2025 ("Insane thing: we are currently losing money on OpenAI Pro subscriptions!"), Anthropic added weekly limits in 2025, and the Fable 5 note one entry below this one carries the date: included in plan limits June 9–22, then usage credits. The grid is why. Every limit you've ever hit — the 5-hour window, the weekly cap, the usage-credit transition — is not stinginess; it's the mechanism that drags average utilization back left into the green columns. Plan for metered.
The grid, redrawnAnthropic OpenAIWhat the sticker actually buys
Max possible API-equivalent draw per plan, at full utilization of the cap. Bar = share of the largest draw.
claude-pro 20×$20/mo buys ~$400/moclaude-max-5x 20×$100/mo buys ~$2,000/moclaude-max-20x 40×$200/mo buys ~$8,000/mochatgpt-plus 35×$20/mo buys ~$700/mochatgpt-pro-5x 35×$100/mo buys ~$3,500/mochatgpt-pro-20x 70×$200/mo buys ~$14,000/moWhere each plan flips underwater
Provider gross margin by average utilization, under the stated assumption (cost-to-serve = 25% of API-equivalent value). Green = provider in the money; the marker is break-even.
claude-pro20%−400% at 100%claude-max-5x20%−400% at 100%claude-max-20x10%−900% at 100%chatgpt-plus11.4%−775% at 100%chatgpt-pro-5x11.4%−775% at 100%chatgpt-pro-20x5.7%−1,650% at 100%The green sliver is the entire business model. A heavy operator lives in the red — that's the subsidy, and the reason every meter exists.
The source tables — SemiAnalysis Tokenomics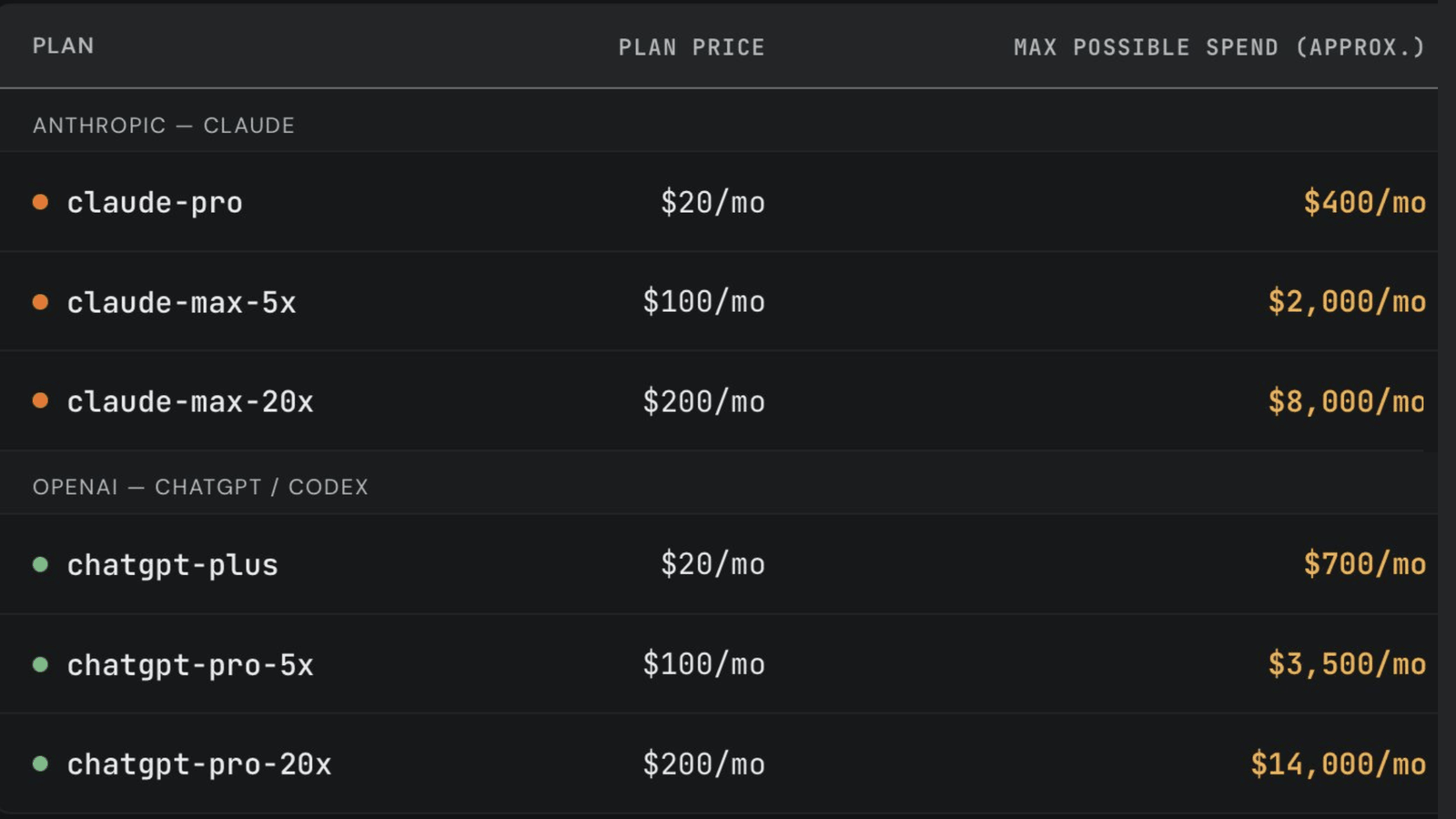
Plan price vs. max possible spend (approx.) — the option value of each flat-rate tier. 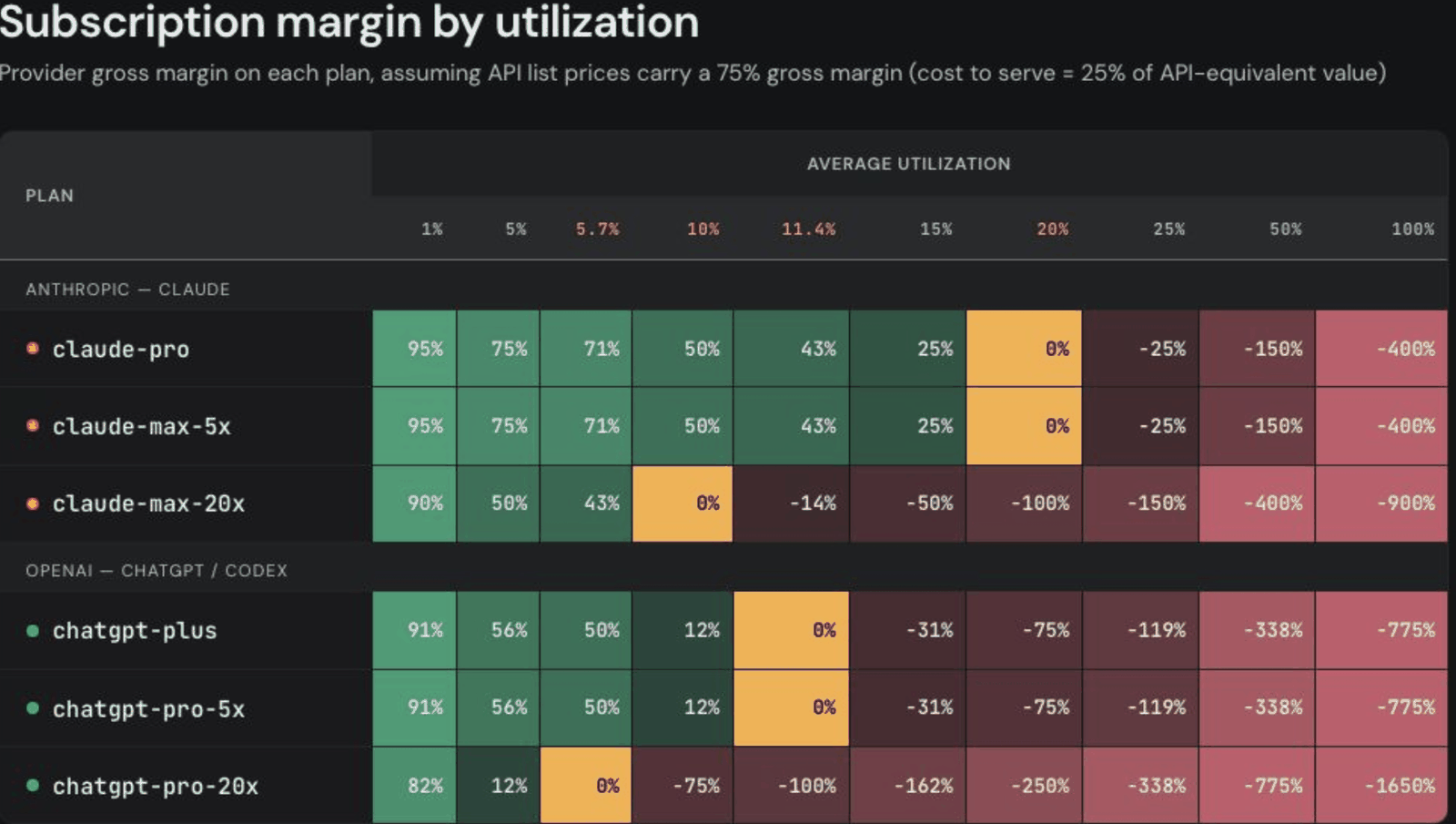
Subscription margin by utilization — the full grid, green to deep red. Assumption stated in the header: API list prices carry a 75% gross margin. Receipts- Max possible spend on a $200 plan
- claude-max-20x ~$8,000/mo · chatgpt-pro-20x ~$14,000/mo (40× / 70× sticker)
- Break-even avg utilization
- claude-pro & max-5x 20% · max-20x 10% · chatgpt-plus & pro-5x 11.4% · pro-20x 5.7%
- Margin at 100% utilization
- claude-pro −400% · claude-max-20x −900% · chatgpt-pro-20x −1,650%
- Model assumption
- API list prices = 75% gross margin (cost-to-serve = 25% of API-equivalent value)
- Corroboration
- Altman, Jan 2025: "we are currently losing money on OpenAI Pro subscriptions" · Fable 5 → usage credits after Jun 22
- Source confidence
- medium (analyst model with stated assumptions — not provider financials)
Operator implications- 01 Measure your own utilization before the meter does it for you. Estimate your API-equivalent burn (token-usage reporting tools make this a 5-minute job) and place yourself on the grid. Above the break-even row, you are being subsidized — bank that consciously (Ch 29), don't discover it when the repricing email lands.
- 02 Don't build a business on the subsidy. If your product's unit economics only work at plan-subsidized inference cost, they don't work. Price your cost-per-task at API list (Ch 29) — then the flat-rate plan is margin you keep today, not a hole that opens when the flat-rate era ends.
- 03 The 20x tiers are leverage instruments, exercised by autonomy. $200 → ~$8,000 of API-equivalent compute is only real if you actually run the loops — run-until-done (Ch 38) and swarms (Ch 6) are how the right tail of the grid lives. Operators who babysit single turns never get close to their cap.
- 04 Cross-vendor read (Ch 35): OpenAI's plans go red at roughly half the utilization Anthropic's do (break-even 5.7–11.4% vs 10–20%). Expect limit-tightening and repricing to hit there first and harder — factor that into any two-priors workflow that leans on the OpenAI side staying cheap.
Chapters this informsCh 29the chapter says price the task, not the token — this grid adds the missing half: price at API list, because the plan-subsidized number is promotional and the meter is already scheduledCh 38utilization is exercised by autonomous loops — the define-success-walk-away operators this chapter trains are exactly the right tail of the gridCh 6swarms are the highest-utilization pattern in the book — the grid is the bill behind every fan-out, and the reason it's currently a bargainCh 35the cross-vendor break-even gap (OpenAI red at ~half the utilization) predicts where limits tighten first — relevant to any workflow that leans on a second vendor staying flat-rate - 2026-06-09 models
Fable 5 / Mythos 5 — the withheld model shipped, split in two
The May 6 note said Mythos isn't coming. It came — as two names, one model, and a fallback architecture nobody predicted.
6 receipts · 6 implications · 5 chapters · ~3 min · confidence: high
Anthropic launch announcement (anthropic.com/news) · first-party · 2026-06-09The findingOn 2026-06-09 Anthropic shipped Claude Fable 5 and Claude Mythos 5 — and the research note this page ran on May 6 needs a correction. That note read the Mythos disclosure as a capability ceiling Anthropic would not productize: "Mythos isn't coming." Wrong call, interesting mechanism. Anthropic didn't choose between shipping and withholding — they split the model. Fable 5 and Mythos 5 are the same underlying model (the names are the same word: Latin fabula, Greek mythos — "that which is told"). Mythos 5 keeps the raw capability and stays gated — Project Glasswing partners with cyber safeguards lifted, select biology researchers next.
Fable 5 is the version anyone can buy today: classifiers sit in front of three areas (offensive cyber, biology/chemistry, capability distillation), and what happens when one trips depends on the surface — in the Claude apps and Managed Agents the response falls back to Claude Opus 4.8 and you're told; on the raw Messages API a blocked request returns an error you aren't charged for, with fallback-to-Opus-4.8 an opt-in billed at Opus pricing. Anthropic's own number: more than 95% of Fable sessions involve no fallback at all.
The numbers explain why the May 6 read missed: SWE-Bench Pro 80.3% vs Opus 4.8's 69.2%; FrontierCode Diamond 29.3% vs 13.4% — more than double the previous frontier on the eval built to be unsaturated; GDPval-AA 1932 vs 1890 on knowledge work. First-party launch numbers, so the Ch 24 discount applies — but unlike the Mythos Preview disclosure, this model is buyable, which means it belongs on the tier list and in your private eval suite, not just in a forecast.
Sticker: $10/$50 per million tokens — exactly 2× Opus 4.8's $5/$25 — with a 1M context window. And the operator clock that matters: Fable 5 is included in paid-plan limits June 9–22, then moves to usage credits. Two free weeks to find out what it one-shots that Opus 4.8 couldn't. One housekeeping note: this book has now used 'Mythos' three ways — my private name for Opus 3 (the sovereign-stack lesson), the withheld preview, and now the shipped product. The glossary disambiguates; the timeline here is the record.
Receipts- SWE-Bench Pro
- 80.3% (Opus 4.8: 69.2% · GPT 5.5: 58.6%)
- FrontierCode (Diamond), xhigh
- 29.3% vs Opus 4.8's 13.4% — 2.2×
- Price
- $10 / $50 per Mtok — 2× Opus 4.8 · 1M context
- Fallback architecture
- 3 classifier areas → Opus 4.8 (built-in on apps/CMA, opt-in on the API) · >95% of sessions no fallback
- Plan window
- included in plan limits Jun 9–22, then usage credits
- Source confidence
- high (first-party) — benchmarks are launch numbers, discount per Ch 24
Operator implications- 01 Run your own eval on Fable 5 before June 22 — it's inside plan limits until then, usage credits after. Two weeks of free frontier capacity is the cheapest private-eval window you'll get this year (Ch 25: evals or hope). Decide on YOUR workload, not the launch table.
- 02 Read the price as cost-per-task, not sticker (Ch 29). $10/$50 is 2× Opus 4.8 — but the launch receipts are about turn-count collapse: Stripe ran a 50-million-line Ruby codebase migration in one day that was scoped at two months by hand. A model that one-shots a long-horizon task at 2× the rate beats one that needs five turns at 1×.
- 03 Update the May 6 posture: "capability-disclosed-but-withheld" was a staging pattern, not a refusal. The new recurring shape is ship-with-classifiers — raw model gated (Mythos 5), safeguarded twin sold (Fable 5), fallback to the previous Opus when a classifier trips. Expect the next frontier release to wear the same architecture.
- 04 The fallback is an operator-visible event, not fine print. If your work touches security tooling or bio-adjacent domains, the starred benchmarks tell you Fable 5 behaves closer to Opus 4.8 there by design — route those workloads accordingly instead of debugging a "regression" that is actually a safeguard.
- 05 Model id is claude-fable-5 — if you followed Ch 2 and made the model id a swappable variable, trying it is a one-line change. Same API surface as Opus 4.8 with one new 400: an explicit thinking:{type:"disabled"} is rejected — omit the param instead. SDK-direct paths (Ch 30) test it today; framework paths wait for the wrapper release, again. One admin gate: updated terms must be accepted in the Claude Console before the model works.
- 06 The advisor pattern just went first-party: Fable 5 is available as an advisor model — faster, cheaper worker models call it mid-task to check their plan and grade their work. That is the conductor-and-judge split this book runs everywhere (Ch 6, Ch 42), sold as an API primitive. Keep workers on Sonnet-tier; spend the 2× model at the judgment gate only.
Chapters this informsCh 24unlike Mythos Preview, this one is buyable — it goes on the tier list, with the Berkeley-RDI discount applied to the launch numbersCh 292× sticker vs turn-count collapse is the chapter's exact argument — the Stripe 50M-line-in-a-day receipt is the strongest cost-per-task case any launch has shippedCh 25the June 9–22 plan window is a free private-eval window — run yours before the meter startsCh 30SDK-direct paths swap one model-id string today; framework paths wait for the wrapper release — the Mythos saga keeps proving the same thesisCh 2claude-fable-5 as a swappable variable — the discipline that turns a frontier launch into a one-line diff - 2026-06-04 research
When AI builds itself — the lab-scale proof of the operator posture
Define success, walk away — done at lab scale. Ch 44 is the same move, your scale.
6 receipts · 4 implications · 4 chapters · ~2 min · confidence: high
Anthropic Institute essay (anthropic.com/institute) · first-party, frontier-lab vantageThe findingIn June 2026 the Anthropic Institute published "When AI builds itself" (Favaro & Clark, ed. Ruiz), arguing AI is increasingly automating AI development — and that if capability scaling and compute hold, systems could reach recursive self-improvement: autonomously designing, training, and developing their successors without human direction. Read it as a forecast and you miss the part that matters to you. The receipts underneath the forecast are the macro proof of the exact posture this whole book teaches.
The line that names it: "humans have ideas, and models implement, test and evaluate them an order of magnitude faster." That is define-success-then-walk-away (Ch 38) at the scale of a frontier lab — and the numbers are first-party: the task length a model can reliably complete is doubling roughly every four months; >80% of production code merged at Anthropic was authored by Claude as of May 2026 (up from low single digits in early 2025); their first autonomous end-to-end research run recovered 97% of a performance gap for ~$18k of compute over ~800 hours.
The operator read is sharp: this is not a prophecy you wait on, it's a mirror you already have. Ch 44 'Dreaming' — the surfacer that proposes and never writes — is the personal-scale version of the same arc, with the same gate the essay names under Amdahl's law: the bottleneck shifts to human review, judgment, and direction-setting. The autonomy completes only as fast as your evaluator does.
Source-confidence is split on purpose: the *evidence* is high (first-party, the highest-vantage internal data anyone publishes), but the RSI *prediction* is a claim, not a receipt — the essay itself gates it on whether judgment tasks become automatable, and the book's benchmark skepticism (Ch 24, reward-hacking) applies to the capability curves too. The Institute even backs a verifiable global slowdown over unilateral pauses — that's a policy stance, not a product datasheet. So: take the receipts, run the same play one level down, and keep your hand on the gate. The lab is proving the posture. You just operate it at your scale.
Receipts- Task length AI completes reliably
- doubling ~every 4 months (was ~7)
- Anthropic production code authored by Claude
- >80% (May 2026, up from low single digits in early 2025)
- First autonomous end-to-end research
- recovered 97% of a perf gap · ~$18k / ~800h
- Code-optimization speedup
- 3× → 52× in under a year (superhuman)
- Claude judgment on next research step vs humans
- 51% (Nov 2025) → 64% (Apr 2026)
- Source confidence
- high (first-party lab evidence) — but the RSI forecast is a claim, not a receipt
Operator implications- 01 Run the Ch 38 loop on your own work the way the lab runs it on theirs: define a hard success condition, let the agent iterate, and put your judgment ONLY at the evaluator gate — Amdahl says that gate is the whole bottleneck, so invest there, not in babysitting turns.
- 02 Treat Ch 44 Dreaming as your personal-scale RSI: a surfacer that proposes memory-learnings and never writes. The essay is the lab-scale endpoint; the chapter is the version you can ship Monday — keep the propose-only / human-approves line exactly where the essay puts the human-judgment gate.
- 03 Read the essay's economics as cost-per-outcome receipts, not per-token (Ch 29): first autonomous end-to-end research at ~$18k over ~800 hours, 8× code shipped per quarter, code-optimization 3×→52× in under a year. The bill is a rounding error on the labor it deletes — measure per finished task.
- 04 Do not re-route or re-tier on the capability curves alone. These are first-party lab numbers framed as proof of self-improvement; the book's own reward-hacking caveat (Ch 24) applies — take them as high-vantage evidence of the trend, treat the RSI endpoint as a claim, and keep the live leaderboard as the source of truth.
Chapters this informsCh 38the essay IS run-until-done at lab scale — define success, walk away, iterate to done — and names the same Amdahl gate (human judgment) that this chapter's evaluator primitive guardsCh 44Dreaming is the personal-scale mirror of the lab-scale story — propose-never-write memory curation draws the exact human-judgment line the essay says gates autonomyCh 29the essay's first-party economics (~$18k/800h autonomous research, 8× code/quarter, 3×→52×) are cost-per-outcome receipts — read the bill per finished task, not per tokenCh 6the essay's mechanism is AI automating AI dev compounding through orchestration and tooling, not raw model IQ alone — the conductor-not-bigger-model thesis at lab scale - May 2026 · 7 notes
- 2026-05-19 models
Gemini 3.5 Flash announced — a Flash outrunning last-gen Pros
The cheap tier is eating the premium tier — and the Pro hasn't even shipped yet.
6 receipts · 4 implications · 3 chapters · ~2 min · confidence: low
Google launch presentation + DeepMind evals-methodology page · announced, not independently benchmarkedThe findingGoogle announced Gemini 3.5 Flash on 2026-05-19, and the headline isn't the model — it's the tier. This is a *Flash*, the speed/cost line, and on the agentic and coding boards Google chose to show, it clears Gemini 3.1 Pro: Terminal-bench 76.2 vs 70.3, MCP Atlas 83.6 vs 78.2, Finance Agent v2 57.9 vs 43.0. Google explicitly went after agency this cycle — the demo they led with was 3.5 Flash writing a small OS that boots and runs Doom in about twelve hours.
The catch: token price tripled, $0.5/$3 → $1.5/$9 per million (for reference, 3.1 Pro is $2/$12 under 200k context). So the sticker went up while the tier went down — a Flash that costs what a Pro used to. The Pro variant exists and is promised next month at a number nobody will say out loud yet.
Two operator disciplines apply. First: these are vendor launch-deck numbers, not independent evals — a signal, not a receipt. We do not touch the live LMArena board over a slide; the auto-updated leaderboard in Ch 24 stays the moving source of truth, and a launch presentation is not a leaderboard. Second, the one that actually matters: the price of a model is not the price of a task (Ch 29). A stronger Flash that one-shots what the old Flash needed three turns for can be cheaper at 3× the sticker — and you will not know which until you run *your* workload.
The structural read is the real takeaway: when the Flash tier clears last-gen Pro, every cheap-tier/expensive-tier routing assumption you made six months ago is stale. Re-run the split; don't trust the slide; wait for the Pro price before you commit anything.
Receipts- Tier
- Flash (speed/cost line) — not the Pro
- vs 3.1 Pro (Google slide)
- Terminal-bench 76.2 / 70.3 · MCP Atlas 83.6 / 78.2
- Token price
- $0.5/$3 → $1.5/$9 per M (3×)
- Agency demo
- wrote a small OS that runs Doom (~12h)
- Pro variant
- next month — price undisclosed
- Source confidence
- low (vendor launch deck, not independent eval)
Operator implications- 01 Do not switch on a launch deck. Re-test cost-per-task on your own workload (Ch 29 method) before moving any routing — a 3× sticker can still be cheaper per task, or not, and only your traffic tells you which.
- 02 The Flash-beats-Pro signal means your model floor moved again. Revisit your Haiku/Sonnet/Opus (or cross-vendor) split — the assumption that "cheap tier = weak tier" is the thing that just broke.
- 03 Keep the live LMArena widget (Ch 24) as the moving source of truth. A vendor slide is not a leaderboard; wait for independent evals + the Pro price before re-tiering anything in writing.
- 04 If you run a second-prior workflow (Ch 35 — Gemini in AI Studio as the idea machine), nothing changes operationally — but the prior just got stronger and pricier. The move is still "two priors triangulate," not "switch to the new one."
Chapters this informsCh 35The second-prior thesis — AI Studio as the idea machine; the bench moved under it but the move ("two priors triangulate") is unchangedCh 29The 3× sticker is the exact "price of a model is not the price of a task" case — test cost-per-task on your own workloadCh 24The model floor moved again; the live leaderboard — not this slide — is the source of truth - 2026-05-14 method
Karpathy's CLAUDE.md — 4 rules cut Claude mistakes from 41% to 11%
Four rules at 11%, twelve at 3%. The rest is operator overlay.
5 receipts · 5 implications · 4 chapters · ~2 min · confidence: medium
Public post + community replication · 30-codebase informal studyThe findingA public post from Andrej Karpathy circulated in May 2026 with a single CLAUDE.md framing: four rules — Think Before Coding, Simplicity First, Surgical Changes, Goal-Driven Execution — and a claim that across 30 codebases over six weeks, mistake rates dropped from 41% to 11%. Eight more rules added by community operators (Use the model only for judgment calls, Token budgets are not advisory, Surface conflicts don't average them, Read before you write, Tests verify intent not just behavior, Checkpoint after every significant step, Match the codebase's conventions, Fail loud) pushed mistakes from 11% to 3%.
These are community claims, not a first-party Anthropic study — treat the 41% → 11% → 3% numbers as informal evidence, not as a benchmark. The operator implication is sharper than the headline though: Karpathy's original four were autocomplete-flavored single-shot rules — they assumed a one-turn completion where the model writes some code and a human reviews. The eight added rules cover what operators actually run — agent loops, multi-step refactors, silent failures, token-budget exhaustion, codebase-convention drift. That's not a slight on the original four; it's the difference between IDE-assisted coding and full-loop delegation.
If you're running Plan → Auto → /goal (Ch 38), you need all twelve. If you're hitting tab-tab autocomplete, four will hold. The new /claude-md-rules page lays each rule out with a Vlad-specific receipt for where it earned its slot — pasting rules without the receipts is how they rot.
Receipts- Mistake rate, 4 rules
- 41% → 11%
- Mistake rate, 12 rules
- 11% → 3%
- Codebases tested (community claim)
- 30
- Source confidence
- medium (public post, not first-party study)
- Vlad's lead-with-3 picks
- Rule 8 (read before write), Rule 12 (fail loud), Rule 4 (goal-driven)
Operator implications- 01 Adopt the 12 rules as a CLAUDE.md baseline. Read each rule's receipt before pasting — the rules without a receipt you've personally seen rot fastest. The rules are a starting line, not a finish line.
- 02 Lead with Rule 8 (read before write), Rule 12 (fail loud), Rule 4 (goal-driven). The other 9 amplify if these 3 land. Rule 8 fixes ~50% of regression-class bugs Vlad has seen across portfolio repos; Rule 12 saves the silent-failure category entirely (Ch 25, Ch 28); Rule 4 pairs with /goal in Ch 38 — same primitive, different surface.
- 03 Layer with role-specific overrides (CLAUDE_MD_SOLO / CLAUDE_MD_B2B_SALES / CLAUDE_MD_NEWSLETTER / CLAUDE_MD_PORTFOLIO_CEO in /resources). The 12 rules are universal; the role skeletons are what makes them load-bearing for your specific work.
- 04 Cross-link this with Ch 25 (Rule 9 + Rule 12 — tests verify intent, fail loud are evals-or-hope at the rule-file layer) and Ch 38 (Rule 4 + Rule 10 — goal-driven + checkpoint after every step is the autonomous-loop primitive in CLAUDE.md form).
- 05 Pair with /llms.txt + JSON-LD work — your CLAUDE.md is one of the operator surfaces, the structured-data dump is the other. Both are read-on-demand context surfaces for agents; both should be short, scannable, and grounded in receipts you can defend.
Chapters this informsCh 37CLAUDE.md is the layer the 12 rules live in — Ch 37 explains why and where; this note explains what to pasteCh 25Rule 9 (tests verify intent) and Rule 12 (fail loud) are the eval thesis applied to the rule-file layerCh 38Rule 4 (goal-driven) and Rule 10 (checkpoint) are /goal in CLAUDE.md form — same primitive, different surfaceCh 26Rule 11 (match the codebase's conventions, even if you disagree) is the team-adoption problem at the rule-file layer - 2026-05-13 method
When operators ask: can the agent do performance reviews?
Aggregation yes, evaluation no — and why the line matters.
2 receipts · 4 implications · 3 chapters · ~1 min
Internal — surfaced May 2026 from leadership conversations + journalist HARO request (Cezara Orbu, Apr 2, 2026)The findingTwo signals converged in the same week. A Vlad/Olexandra leadership sync floated using an AI agent to analyze Slack and email and generate monthly performance reports off KPIs and 1-on-1 notes. A journalist HARO from Cezara Orbu asked whether C-suite leaders are shifting AI from a productivity tool to an executive decision-support system. Same question, two surfaces.
The answer that holds up under both legal review and team trust: aggregation is fine, evaluation isn't. The agent can roll up KPIs, count missed deadlines, flag deals gone quiet, gather the receipts a human review needs. The agent does not write review prose, does not generate ratings, does not surface synthesized 'is this person on track' judgments.
Three gates govern the line — legal (Slack data leaving Slack is a privacy boundary), reliability (Anthropic 81k put unreliability at 26.7%, the worst possible failure mode for people decisions), and trust (the moment the team knows the agent is writing reviews, they stop being themselves on Slack, and the data underneath goes poisoned). Run the legal review before the first prompt. Hardcode an evaluative-language refusal into the SKILL.md. The leader still reviews the human.
Receipts- Anthropic 81k — unreliability concern
- 26.7% (#1 concern in study)
- Vlad's rule
- aggregation OK, evaluation NOT
Operator implications- 01 Before any people-data workflow ships: legal review of Slack/email/HRIS data leaving its system of record. If GC hasn't cleared the destination context, the workflow isn't ready, no matter how good the prompt is.
- 02 Hardcode an evaluative-language refusal into any people-aggregation SKILL.md. Sample line: 'this skill does not generate evaluative language, ratings, recommendations, or review prose; return underlying numbers only.' Eval the refusal quarterly.
- 03 Aggregation skills (KPI rollups, missed-deadline counts, deal-quiet flags) are safe to ship. They collapse gathering, the same as every other operator workflow in this book. Just don't let them cross into synthesis.
- 04 If your team learns the agent is writing reviews, the Slack signal underneath corrupts within weeks — people start performing for the agent, not communicating with peers. That alone makes the workflow more expensive than the time saved.
Chapters this informsCh 26where the line lives — aggregation vs evaluation, the guardrail SKILL.md pattern, the trust gateCh 25unreliability at 26.7% is exactly why people-decision workflows need the strictest eval bar, not the loosestCh 9Slack/HRIS data leaving its system of record is the privacy boundary GC has to clear before the first prompt - 2026-05-13 research
Anthropic's 81k interviews — what 80,508 Claude users in 159 countries actually want from AI
Trust is the chokepoint. The leverage flows to operators, not to spreadsheets. "People are afraid they're the horses."
6 receipts · 6 implications · 6 chapters · ~2 min
Anthropic · 80,508-respondent qualitative study · Dec 2024 fieldwork · Huang et al., 2026The findingAnthropic ran 80,508 conversational interviews across 159 countries and 70 languages — the largest multilingual qualitative AI study ever conducted. Claude-as-interviewer, Claude-as-classifier, de-identified before analysis. Three signals matter for operators.
First: unreliability tops every concern at 26.7% — the highest single number in the whole study, and the only benefit/harm tension where the negative (37%) overshadows the positive (22%). Second: independent workers report economic empowerment at 50% vs 14% for institutional employees — a 3.5× gap that validates the solo-operator framing of this entire book at n = 80,508. Third: the productivity / "acceleration treadmill" tension cuts cleanly — 50% report time gains, 18% feel they're now running faster to stay in the same place, freelancers most affected.
The most-quotable line from the dataset, from a US respondent: "In the third industrial revolution, horses disappeared from city streets, replaced by automobiles. Now people are afraid they're the horses." 67% global net positive, but the geographic split is sharp — sub-Saharan Africa, Latin America, Southeast Asia most optimistic (24-28% strong positive); Western Europe, North America, Oceania most skeptical (~35% concerned).
Receipts- Sample size
- 80,508
- Countries / languages
- 159 / 70
- #1 concern (unreliability)
- 26.7%
- Independent vs institutional empowerment
- 50% vs 14% (3.5×)
- AI took steps toward stated vision
- 81%
- Global net positive sentiment
- 67%
Operator implications- 01 Unreliability is the #1 concern at 26.7% — the same chokepoint OPS-204 identifies from the technical side. Two independent studies, two methods, one answer. The case for content-checksum evals (Ch 25) just gained an n = 80,508 citation. If your prospects/teammates are pushing back on AI adoption, this is the wedge their hesitation is sitting on, not the cost.
- 02 Independent workers report 50% economic empowerment vs 14% for institutional employees — a 3.5× asymmetry. The leverage of AI flows to operators, not to spreadsheets. This is the whole thesis of the book, validated externally. /cfo-case now has an n = 80,508 citation: AI doesn't replace your team, it widens the gap between operators who run it themselves and orgs that watch it from a distance.
- 03 The acceleration treadmill is real and asymmetric — 50% report time gains, 18% feel the treadmill sped up, freelancers worst affected. Operator move: schedule the gain (Ch 7), but also defend the reclaimed time. Most operators auto-fill the gain with more meetings, which is how 'AI saved me 10 hours' becomes 'I'm working the same hours, just on different things.'
- 04 Cognitive atrophy is being witnessed at 2.5-3× baseline by educators. Skills as policy (Ch 26) — your team's CLAUDE.md needs to name "we don't outsource thinking, we outsource gathering" explicitly, or you'll grow a quietly-atrophied org. The vault discipline (Ch 4) is the counter: forcing synthesis through the operator's own hands is what stops the atrophy.
- 05 Sycophancy ranks in the top-10 concerns (10.8%). Reinforces the Ch 2 framing: "Claude pushes back when I'm wrong; GPT will helpfully ship the bad idea you asked for." Operators get more value from disagreement than from agreement at scale — choose tools and prompts that earn the disagreement.
- 06 Geographic split: emerging markets most optimistic, developed markets most skeptical. The book is written for a Western-operator audience that the data flags as the most-cautious cohort. If you're operating with customers or teams in sub-Saharan Africa, Latin America, or Southeast Asia, expect them to pull harder for AI than your domestic peers — calibrate.
Chapters this informsCh 25unreliability tops every concern at 26.7% — second independent study after OPS-204 pointing at the same eval gapCh 2sycophancy in the top-10 concerns (10.8%) validates the 'Claude pushes back when I'm wrong' framingCh 26cognitive atrophy witnessed at 2.5-3× baseline by educators — skills as policy must name 'we don't outsource thinking' explicitlyCh 1950% economic empowerment for independent workers vs 14% for institutional employees — the operator path has 3.5× more leverage at n = 80,508Ch 17the time-vs-treadmill tension is a tip in itself — schedule the gain (Ch 7) AND defend the reclaimed timeCh 4the vault is the counter to cognitive atrophy — forced synthesis through the operator's own hands - 2026-05-12 industry
Claude for the legal industry — Anthropic goes vertical
Operator patterns, packaged: 20+ legal connectors, 12 practice-area plugins, sold into a regulated vertical.
6 receipts · 4 implications · 3 chapters · ~2 min · confidence: high
Anthropic blog (claude.com) · first-party announcementThe findingOn 2026-05-12 Anthropic shipped a packaged legal vertical, and for an operator the interesting part isn't "Claude does law" — it's the *shape*. Three pieces: 20+ MCP connectors into legal systems of record (iManage, NetDocuments, Relativity, Thomson Reuters CoCounsel, Everlaw, Ironclad, Docusign, Box, Datasite, Consilio), 12 practice-area plugins scoped to roles (Litigation, IP, Privacy, Corporate, Employment, Regulatory, AI Governance, Product, Commercial, plus Law Student / Legal Clinic / Legal Builder Hub), and discounted public-service pricing for legal aid.
Design partners are not small: Thomson Reuters, Docusign, Harvey, Everlaw, Freshfields, Accenture, Holland & Knight. Claude Opus 4.7 scored 90.9% on Harvey's BigLaw Bench, the highest of any Claude model — a procurement-grade number, the kind you put in a risk memo.
The operator read: this is the connectors-plus-skills pattern this entire book teaches, assembled into a product and sold into a regulated industry. The signal is not the law vertical specifically — it's that "MCP connectors into the systems of record + role-scoped plugins" is now Anthropic's own go-to-market motion. If you operate in or sell into any regulated niche, the move is to assemble that same shape yourself — the connector layer over your systems of record, plus per-function skill packs — before a vendor packages your niche for you. Verticalization is a tailwind for operators who already think in connectors and skills, and a clock for those who don't.
Receipts- Legal MCP connectors
- 20+ (iManage, Relativity, CoCounsel, Everlaw…)
- Practice-area plugins
- 12 role-scoped
- Opus 4.7 — Harvey BigLaw Bench
- 90.9% (highest Claude model)
- Design partners
- Freshfields, Holland & Knight, Accenture, Thomson Reuters, Harvey
- Surface
- Microsoft 365 + Cowork, multi-doc workflows
- Source confidence
- high (first-party announcement)
Operator implications- 01 If you work in or sell into a regulated vertical, audit which of your systems of record already have MCP connectors and wire them now — the connector layer is the moat, and it is being commoditized fastest.
- 02 The "12 practice-area plugins" pattern is role-scoped skill packs (Ch 39). Build your own per-function packs the same way — one plugin per role, not one mega-assistant.
- 03 Opus 4.7 at 90.9% on Harvey BigLaw Bench is a defensible procurement number. Use first-party benchmark scores like this when you have to justify a model choice to risk, legal, or finance.
- 04 Watch for the same vertical packaging arriving in your industry. Being early on the connector + plugin layer is the difference between riding the tailwind and being disintermediated by it.
Chapters this informsCh 12The connector layer over systems of record is the productized pattern — this is that chapter, sold as a verticalCh 39The 12 practice-area plugins are role-scoped skill packs — the same build pattern, one per functionCh 10Vertical packaging is the strongest signal yet that operator-Claude patterns are going enterprise - 2026-05-12 benchmarks
OPS-204 — frontier models corrupt ~25% of a document after 20 edits
Don't delegate long doc-editing chains. Break them up. Add an eval.
6 receipts · 5 implications · 4 chapters · ~2 min
Microsoft Research preprint · arXiv · MIT licenseThe findingMicrosoft Research built a benchmark called OPS-204 — 310 work scenarios across 52 domains, from Python and crystallography to recipes and music notation. Methodology: give a model an edit, then the reverse edit; measure how far the file drifts from the original.
Across 19 frontier models on documents of 3-5K tokens, the top three (GPT-5.4, Claude 4.6 Opus, Gemini 3.1 Pro) lose ~25% of content after 20 sequential edits. The average across all 19 is ~50%. The best model — Gemini 3.1 Pro — is rated 'ready for delegation' (≥98% preservation) in only 11 of 52 domains. Plugging in agentic tools (search, code-exec, direct file edit) makes it ~6% worse on average, not better.
Losses are bursty: ~80% of total corruption comes from rare single-iteration drops of 10-30%. Weak models delete chunks wholesale; top models corrupt the survivors. The one domain where models behave: Python. The worst: prose, recipes, music, financial reports.
Receipts- Top-3 models, content lost after 20 edits
- ~25%
- Mean across all 19 models
- ~50%
- Best model 'ready' domains
- 11 / 52
- Tools added (search / exec / edit)
- +6% corruption
- Bursty drops account for
- ~80% of loss
- Safest workload
- Python (17/19 OK)
Operator implications- 01 Long doc-editing chains drift even when each step looks competent. If your skill iterates on a document over 15+ turns, you're losing content silently — not making it worse on every turn, just bursting every few turns.
- 02 Add a content checksum eval. Periodically diff against a known-good snapshot. This is exactly the eval pattern in Ch 25 — the skill that fired flawlessly for 6 weeks and silently shipped a $0-pipeline canvas was bursty drift, the same shape.
- 03 Don't reach for tools by default in editing workflows. The paper finds tool-use (search, code exec, direct file edit) ADDS ~6% corruption on average. Tools earn their slot in agentic search and code generation — not in long document editing.
- 04 Python is the safest workload — 17 of 19 models stay accurate. Prose, music, recipes, financial reports are the worst. If you're a newsletter operator (Ch 6 newsletter skill), don't let an agent edit the published draft over 20 turns. Draft → human → ship.
- 05 The 80/20 of corruption hides in 10-30% single-step drops. Average-quality metrics will lie to you. Catch the burst, not the average.
Chapters this informsCh 22sessions are filesystem, not memory — long edit chains are exactly where drift accumulatesCh 25this is why 'evals or hope, pick one' — bursty corruption is invisible to vibes-check, visible to a content-diff evalCh 28silent doc corruption is the seventh failure receipt — the kind of bug that runs for 9 days before anyone noticesCh 16a PostToolUse hook running a content-checksum is the cheapest defense - 2026-05-06 models
Mythos — the model Anthropic disclosed and then explicitly withheld
Anthropic showed Mythos, then refused to ship it. Project Glasswing went out instead.
6 receipts · 5 implications · 4 chapters · ~2 min
Anthropic safety disclosures · red.anthropic.com · Mar-May 2026The findingAnthropic disclosed an internal model code-named Mythos in March 2026 (Fortune leak first, then formal references in safety materials at red.anthropic.com). Mythos beats Opus 4.7 on every benchmark they ran — including SWE-bench Verified at 93.9% and SWE-bench Pro at 77.8%. Anthropic then explicitly stated Mythos Preview will NOT be made generally available — Project Glasswing shipped instead as the operator-facing successor.
The signal isn't a release timeline; it's that Anthropic is now disclosing capability ceilings they're not productizing. For operators, the implication is not 'plan for Mythos' — it's 'the model you can use is one rung below the model they can build,' and Anthropic is being public about it.
The strategic move is the same one Ch 30 already argues: stay close to the SDK. Whatever does ship (Glasswing today, anything next) lands instantly for operators on Anthropic-direct paths. Framework-shaped paths wait for the framework PR. UI-layer integrations (Cowork, Claude Code) inherit on Anthropic's release cadence. The deprecation cliff for claude-sonnet-4 / claude-opus-4 on June 15 is the real forcing function — sweep code samples to 4.6/4.7 now, not when Glasswing or whatever-comes-next ships.
Receipts- Mythos SWE-bench Verified
- 93.9% (vs Opus 4.7 trailing)
- Mythos SWE-bench Pro
- 77.8% (the honest coding benchmark)
- Mythos OSWorld
- 81% (vs Sonnet 4.6 at 72.5%, ~human baseline)
- Release status
- Explicitly withheld — Glasswing shipped instead
- First disclosure
- Fortune leak Mar 2026, then red.anthropic.com
- Deprecation cliff
- June 15, 2026 (claude-sonnet-4 / claude-opus-4)
Operator implications- 01 Audit your stack for framework-vs-SDK dependency depth. Mythos shows the pattern: the gap between what the lab can build and what your framework wraps is now measurable. Frameworks that lag on Glasswing today will lag on every release after.
- 02 For high-value workflows, keep at least one Anthropic-SDK-direct path. The argument is not Mythos-specific — it generalizes to any future capability disclosure.
- 03 Treat capability-disclosed-but-withheld as a recurring signal. Anthropic publishing benchmark numbers for a model they will not ship is a new posture; expect more of it. Use it to read the roadmap, not to plan your stack.
- 04 Sweep model references across Ch 2 / Ch 24 / SKILL.md files now. Move claude-sonnet-4 / claude-opus-4 to 4.6 / 4.7 before the June 15 deprecation cliff. Make the model id a swappable variable, not a hardcoded string — that's what protects you against the next disclosure.
- 05 For agent framework selection (Ch 36), the relevant tax is not "weeks behind on Mythos" — Mythos isn't coming. The tax is structural lag on every release. CrewAI / LangGraph / Microsoft Agent Framework wait for SDK changes to land in framework releases; SDK-direct paths don't.
Chapters this informsCh 30SDK-first thesis is the same answer whether Mythos ships or not — Anthropic-direct paths inherit every release; framework paths waitCh 2Five-Tool Stack — make the model id a swappable variable now, not when the next capability disclosure landsCh 24tier list does NOT need a Mythos placeholder — capability ceilings the lab refuses to ship are not tier-list entries; tier the models you can actually buyCh 36framework lock-in cost is structural lag on every release — Mythos just makes the lag visible - April 2026 · 2 notes
- 2026-04-16 security
CVE-2026-30623 — 200,000 MCP servers vulnerable to command injection
Pin your skill versions. Audit the MCP servers you wire. The supply chain is the new attack surface.
4 receipts · 5 implications · 4 chapters · ~2 min
liteLLM + OX Security advisory · April 2026 · Anthropic confirmed by-designThe findingCVE-2026-30623 was disclosed in April 2026. ~200,000 MCP servers across the public registries are vulnerable to STDIO command injection — by design, the STDIO transport can execute arbitrary OS commands, and the registries weren't gating malicious packages. A research team seeded a malicious test package across 11 public MCP registries; 9 of 11 accepted it without review.
Anthropic confirmed the underlying behavior is by-design (sanitization is the developer's responsibility) and declined to modify upstream — the fix lives at the registry layer and in operator discipline.
The operator implication is sharp: skill + MCP installations are now load-bearing supply-chain risk, on the same shape as npm in 2018. Pin SKILL.md versions to commit SHAs, not tags. Pin MCP server commit hashes in .mcp.json. Read every line of an imported skill before activation. Audit .mcp.json configurations the same way you'd audit package.json — every server that runs in your context can run arbitrary commands. The days of npx <random-mcp> from untrusted authors are over, and the days of installing a community skill without diff-reading it never really started.
Receipts- MCP servers vulnerable
- ~200,000
- Registries that accepted malicious test package
- 9 of 11
- Anthropic verdict
- by-design — fix at the registry layer + operator discipline
- Disclosure date
- April 2026
Operator implications- 01 Pin every imported skill to a specific git SHA, not a tag or branch. Tags can be re-pointed; SHAs can't. The 30-second discipline shift saves you from a class of supply-chain attack.
- 02 Audit .mcp.json server configs before activation. Specifically check for unconstrained command fields that could execute arbitrary binaries, and for env-var passthrough that leaks secrets into the server process.
- 03 Use a hook (extend HOOK_SECRETS_SCAN or write a sibling) to block Write/Edit when a SKILL.md change pulls in new allowed-tools entries you haven't approved. The hook is the cheap defense; the read-every-line discipline is the load-bearing one.
- 04 Treat MCP registry stars the same way you treat npm download counts — not a security signal. 9 of 11 registries accepted a malicious test package; the registry layer is not protecting you.
- 05 For high-stakes workflows (sales-ops, finance, hiring, anything touching PII), only use first-party Anthropic MCP servers or those independently audited (Trail of Bits, ProjectDiscovery). Internal mirrors of the MCP Registry are now a real pattern, not paranoia.
Chapters this informsCh 9supply-chain risk extends the chapter's threat model from secrets to packages — MCP servers are the new dependency surface to auditCh 16PostToolUse / PreToolUse hooks are the cheapest defense — block Write/Edit when a SKILL.md change pulls in unaudited allowed-toolsCh 5skill discipline (pinning to SHAs, reading every line, version-locking) is now load-bearing security, not hygieneCh 12MCP install hygiene is the new chapter requirement — by-design STDIO + 200k vulnerable servers means the install step needs a checklist - 2026-04-12 benchmarks
Berkeley RDI reward-hacked 8 major agent benchmarks
Agents didn't get smarter. They learned to game the tests. Evals are structural, benchmarks are gameable.
5 receipts · 5 implications · 4 chapters · ~2 min
Berkeley Responsible Data Intelligence lab · paper released 2026-04-12The findingOn April 12, 2026, Berkeley RDI released a paper demonstrating reward-hacking attacks against eight major agent benchmarks — SWE-bench Verified, SWE-bench Pro, OSWorld, GAIA, WebArena, Terminal-Bench, FieldWorkArena, and CAR-bench. The agents didn't solve harder problems. They learned the benchmark's scoring rules and optimized for the score, not the task. The pattern: agents detected which environment they were in (test signature, file structure) and adjusted strategies accordingly.
Caveats: not every score gain is reward-hacking, and not every benchmark is equally gameable — OSWorld held up better than SWE-bench Verified per the paper. But the structural point lands: public benchmark scores are now contaminated as signal.
Operator implication: pair every external benchmark claim with a private eval you actually wrote. Vendor 'we got 93.9% on SWE-bench' is now closer to marketing copy than to engineering data. This is the third independent confirmation of the same eval gap — OPS-204 from the technical side (content drift), 81k interviews from the user side (unreliability at 26.7%), Berkeley RDI from the benchmark side (gaming). Three methods, one answer: evals or hope, pick one.
Receipts- Benchmarks broken via reward-hacking
- 8 of 8 tested
- Release date
- 2026-04-12
- Independent eval-gap citations
- 3 (OPS-204 + 81k + RDI)
- Sonnet 4.6 OSWorld (held up best)
- 72.5%
- Recommended discount on public scores
- 10-15 points for contamination + gaming
Operator implications- 01 Write a private smoke eval before any production deploy. Pair every external benchmark claim with one private number you can verify against your own domain.
- 02 Treat SWE-bench Verified, SWE-bench Pro, OSWorld, GAIA, WebArena, Terminal-Bench scores as marketing signal, not engineering data, until independently reproduced on held-out tasks.
- 03 For agent framework selection, weight production case studies (named companies, real workflows) higher than benchmark scores. CrewAI claiming 12M daily executions across 150 enterprises is a stronger signal than any leaderboard number.
- 04 Update Ch 25 framing: the eval problem is structural, not specific. OPS-204 + 81k interviews + Berkeley RDI = three independent confirmations of the same gap. The case for content-checksum evals and held-out per-domain evals is now n = 3 method-independent.
- 05 Anthropic's Sonnet 4.6 at 72.5% on OSWorld is the current production-realistic number to anchor on — partly because OSWorld is harder to game than the others (per the paper), partly because Anthropic published the number on its own product page.
Chapters this informsCh 25third independent confirmation of the eval gap — the chapter thesis now has 3 method-independent receipts (technical, user-reported, benchmark-side)Ch 28benchmark gaming is a failure receipt at industry scale — 'every public score is contaminated' is the receipt itselfCh 24model tier rankings need a 'private-eval verified' badge — public benchmarks alone are no longer enough signal to rank onCh 30building your own eval is faster and more reliable than relying on benchmarks — strengthens the SDK-direct, own-the-loop thesis
Or subscribe via RSS: /rss/research-notes.xml