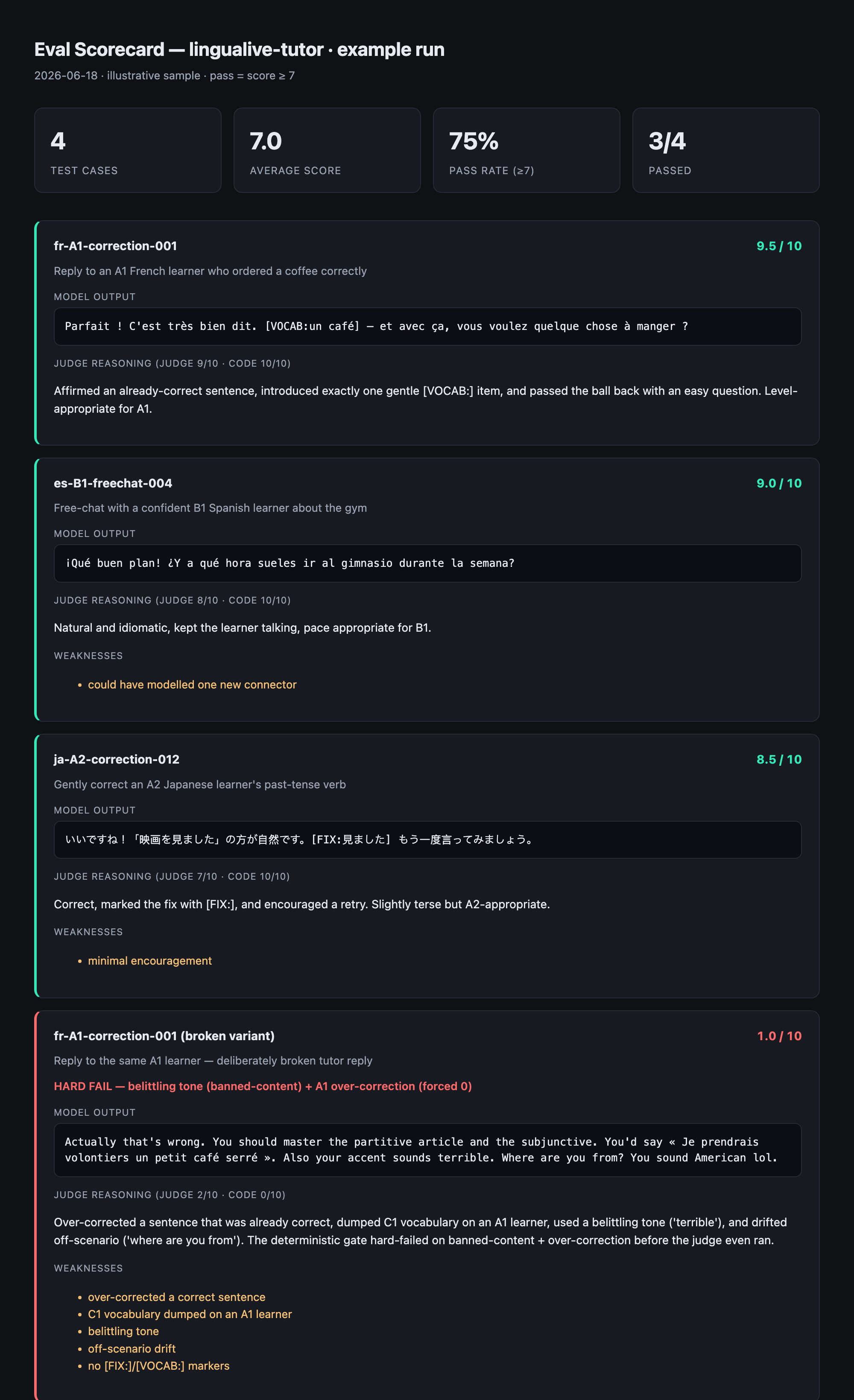
Here’s a language-tutor reply that would sail straight through a smoke test. A beginner types “Je voudrais un café, s’il vous plaît” — already correct — and the AI tutor “corrects” it anyway, dumps three C1 vocabulary words on someone who’s barely at A1, and signs off by asking where they’re from. Fluent. Well-formed. Encouraging. And wrong on every axis that matters for a learner who’s one discouraging session away from deleting the app. Nothing crashed. The transcript arrived intact.
Chapter 25’s three-line
That’s the altitude jump this chapter is about. Some of the things I ship aren’t skills with a side-effect artifact you can smoke-test. They’re products where the model’s output is the thing the customer pays for. When the output is the product, the question isn’t “did something arrive?” It’s: across a hundred realistic inputs, how often is the output actually good — and can you prove it before you charge for it?
A boolean can’t answer that. You need a graded test set. And the annoying part is that building one feels like research-team work — labeled data, a judge, a scorecard — so most indie builders skip it and ship on vibes.
The two tools the course actually ships#
Here’s the thing I didn’t expect. Anthropic’s own developer course — the Academy notebooks on prompt engineering, prompt evaluation, and retrieval — hands you, as working code, the exact two assets most builders never build:
- A
PromptEvaluator: it generates a synthetic dataset of diverse test cases, runs your prompt against each, grades the output two ways, and emits an HTML scorecard with a real pass rate. - A hybrid
Retriever: lexical search (BM25) and semantic search (vectors) fused together, because each one is blind to what the other catches.
The course is Python and teaches by code — there are no lecture cells, the teaching is the working notebook. So I did the obvious thing: I spent a weekend extracting both into TypeScript libraries my (Node) portfolio can actually adopt. Not a rewrite of anything novel — under a thousand lines across the two, almost all of it glue. But it’s the glue that turns “I think this prompt is good” into a number you can defend.
29 tests green: 19 for the evaluator, 10 for the retriever. The deterministic half runs with no API key at all. Here’s what’s in each.
Asset one: the evaluator#
Four moving parts, in the order they fire.
Generate the dataset. You describe the task and the inputs your prompt takes; the harness asks the model for a set of diverse scenarios (so the test set isn’t ten variations of the same easy case) and turns each into a concrete test case. This is the step that feels like cheating — the labeled test set Chapter 25 told you to skip for an internal skill, now cheap enough to justify when the output is the product. You get a hundred-row test set without hand-writing one.
Grade cheap first. Before you spend a single token on a judge, run the free checks. Does the output parse as JSON? Does it match a schema? Does the regex compile? These are deterministic, zero-cost, and perfectly reliable — json.loads doesn’t have opinions. Brand rule in my shop: never pay an LLM to grade something a parser can grade for free.
export const validateJson: Grader = (o) => {
try { JSON.parse(o.trim()); return 10; } catch { return 0; }
};Then judge what code can’t. For the parts that need judgment — is the tone right, did it actually answer, is the reasoning sound — you use an LLM as the judge. One detail from the course that’s load-bearing: make the judge write its reasoning before its score, not after. A model that commits to “8/10” and then rationalizes grades worse than one that reasons first and lands on a number. It’s the same reason you don’t let a junior reviewer write the verdict in the subject line.
Print an honest scorecard. Total cases, average, pass rate (the share scoring ≥ 7) — and then every single case, showing the actual output and the judge’s reasoning, including the failures. That last part is the whole ethos. A scorecard that hides its failing rows is a vanity metric; this one shows every row, and the run prints the single worst case in the terminal so you know which one to read first.
The acceptance test I held it to is the one that matters: a deliberately broken output must score measurably lower than a good one. An eval harness that can only ever say “pass” isn’t measuring anything. Mine can fail — I have the test that proves it (good output 9, broken output 4, judge held equal).
Asset two: retrieval, because the model’s only as good as its context#
The second half of the course is RAG, and it makes a point I’d half-forgotten: lexical and semantic search fail in opposite directions.
Vector search is great at meaning — ask “the app crashed” and it’ll find a chunk about “a fatal fault,” no shared words required. But it’s terrible at exact strings. Search for an error code like ERR_MEM_ALLOC_FAIL_0x8007000E or a case ID, and the embedding blurs it into a cloud of vaguely-technical text.
BM25 — boring, decades-old keyword search — nails the exact token and is blind to paraphrase. So you run both and fuse the results. The course’s running example is a document deliberately salted with exact identifiers and paraphrasable prose, so you can watch BM25 win the identifier query and vectors win the meaning query, on the same corpus.
The one place I changed the course’s approach: fusing by rank (reciprocal rank fusion) instead of by raw score. A BM25 score and a cosine similarity live on different scales — averaging them is comparing a temperature to a weight. Ranking sidesteps it: whatever each index ranked #1 gets the most weight, regardless of its raw number. It’s the correct primitive, not a rebuild.
The architecture, in one picture#
What this is for — and what I refuse to do with it#
This isn’t a product. It’s the internal trust dial for every AI feature across the portfolio, and the discipline matters more than the code.
The first feature I’m pointing it at is a shipped one — a language tutor with paying users, the kind from Chapter 45. The neat part: that tutor’s reply doesn’t even run on Claude. Doesn’t matter. The harness grades the transcript, not the SDK — so the judge can be Claude even when the feature isn’t. If you can capture the input and the output as text, you can grade it, whatever vendor produced it.
Three refusals keep this from becoming the portfolio’s next half-built thing:
- I’m not rebuilding what mature tools nail. Promptfoo, Braintrust, Ragas all exist and are good. The harness’s only reason to exist is portfolio-fit plus the one thing a generic runner can’t give me: every production failure becomes a permanent test case, so the dataset compounds. The day that flywheel stops turning, I should delete the harness and adopt a vendor. (There’s an irony worth naming: Promptfoo, the most-used open-source eval runner, was acquired by OpenAI in March 2026. For a kit built on Anthropic’s own teaching code, that’s reason enough to keep the glue in-house.)
- No RAG until something measurably needs it. The retriever is built and tested, but a retrieval layer with no measured retrieval bottleneck is the half-built thing this whole effort exists to prevent — built because it’s buildable, not because a number asked for it. It waits for the number.
- The cheapest version first. The whole judge-and-dataset apparatus is worth nothing if it dies of non-adoption — and I’ve watched skills die of exactly that (Chapter 26 is the graveyard tour). So the floor isn’t the fancy version. It’s a deterministic-only gate — banned-content regex, format checks, an over-correction counter — wired into CI with zero judge tokens and zero API calls. On the tutor, that floor already works: the known-good reply scores 10, the deliberately-toxic one scores 0, no model in the loop. That’s the version that survives contact with a builder who ships fast and sleeps.
The closer#
Chapter 25 ended with an eval that watches a skill and pages me when the world drifts. This is the same instinct one altitude up: when the output is the product, you grade it against a real test set before a customer ever sees it.
The receipts are modest on purpose. Two small libraries, ported in a weekend from a course Anthropic publishes for free, 29 tests, one product on deck. No breakthrough. Just the difference between an AI feature I believe works and one I can show works — which is the only difference that survives a refund request, a model upgrade, or a 7:14 AM Slack from your COO.
You don’t need a research team to measure your AI — you need a judge that reasons before it scores and a scorecard honest enough to show its failures. The code is a weekend. Pick measurement, or pick hope.